Tác giả bài viết: TRẦN THANH PHƯƠNG1,NGÔ ĐỨC VĨNH2,
HÀ MẠNH TOÀN3,ĐỖ NĂNG TOÀN3*,NÔNG MINH NGỌC4
TÓM TẮT
Trong lĩnh vực thực tại ảo, vấn đề mô phỏng cử chỉ, trạng thái đầu người 3D là một chủ đề nhận được nhiều sự quan tâm bởi khả năng ứng dụng mạnh mẽ trong nhiều bài toán thực tế, chẳng hạn như xây dựng các nhân vật trong phim ảnh, trong các hệ thống phát thanh viên ảo, hướng dẫn viên ảo… Bài báo quan tâm đến vấn đề mô phỏng cử động của mô hình đầu người 3D theo lời thoại tiếng Việt và các nội dung thực hiện có tính chất xâu chuỗi từ những vấn đề về mô hình hóa đầu người 3D đến những thuật toán điều khiển, biến đổi mô hình. Cụ thể, bài báo đã trình bày cách thức xây dựng mô hình mẫu đầu người 3D, cách thức tính toán các vector biến đổi dựa vào các biểu diễn âm tiết riêng lẻcũng như việc biến đổi mô hình theo thời gian, trên cơ sở phân tích nội dung lời thoại tiếng Việt đầu vào để tạo ra được hoạt cảnh mong muốn. Các kết quả thực nghiệm đã chứng tỏ được sự hiệu quả của những đề xuất được đặt ra và là cơ sở cho việc tiến tới những ứng dụng thực tại ảo mô phỏng con người hoàn thiện hơn.
ABSTRACT
In the field of virtual reality, the problem of simulating gestures, 3D head states is a topic that has received much attention becauseof its strong applicability in many real-life problems, such as building personal objects in movies, in systems of virtual broadcasters, virtual guides… The article is interested in the problem of simulating the movements of the 3D human head model followingVietnamese dialogue and the implementation contents with a sequential nature from 3D head modeling problems to control algorithms, transform the model. Specifically, the article presented how to build a 3D human head model, how to calculate transformation vectors based on individual syllable representations as well as model transformation over time, based on analyzing the content of the input Vietnamese dialogue to create the desired animation. The experimental results have proved the effectiveness ofthe proposed proposals and are the basis for moving towards more complete human simulation virtual reality applications.
Keywords: Virtual reality; Morphing; 3D head; Vietnamese dialogue; Handling syllables.
x
x x
1. Giới thiệu
Nghiên cứu mô phỏng con người ảo 3D là một bài toán quan trọng có ý nghĩa trong lĩnh vực thực tại ảo, trong đó vấn đề mô phỏng cử động của mô hình đầu người 3D rất được quan tâm. Đặc biệt gần đây, chủ đề mô phỏng cử động của đầu người 3D dựa trên nguồn âm thanh tiếng nói đưa vào nhằm tạo ra video đầu người nói chân thực đang là chủ đề thu hút nhiều nghiên cứu, đã có nhiều công trình đề xuất nhằm đồng bộ hóa âm thanh với chuyển động của môi[1]–[6]. Tuy nhiên, sự gắn kết giữa âm thanh và chuyển động của đầu người chưa được giải quyết. Trong khi đó, chuyển động tự nhiên và nhịp nhàng của đầu cũng là một trong những yếu tố chính để tạo ra các video đầu người nói sát thực [7], [8].
Chúng ta biết rằng, các cử chỉ, trạng thái biểu hiện khuôn mặt trong một hệ thống mô phỏng con người ảo 3D được tạo ra từ sự chuyển động của hệ thống các cơ nét mặt, kết quả là dẫn đến những biến dạng nhất định trong thời gian ngắn của những bộ phận khuôn mặt như da, lông mày, mũi, mí mắt, và môi[9].Về mặt bản chất, mô hình 3D có thể được hiểu là một tập điểm trong không gian 3 chiều và những thông tin về mối quan hệ giữa các điểm đó. Như vậy, việc biến đổi mô hình đầu người 3D cũng sẽ xoay quanh cấu trúc dữ liệu này.
Ở đây, xét trên việc biến đổi các thành phần trên khuôn mặt nhằm mục tiêu tạo ra những sự thay đổi trên mô hình sao cho phù hợp với lời thoại, mô hình đầu người 3D có thể coi là không có sự thay đổi về liên kết đặc trưng giữa các điểm và chất liệu ảnh. Những sự thay đổi chỉ là những sự dịch chuyển có giới hạn và có sự ràng buộc theo những tiêu chí nhất định của các điểm trong mô hình đầu người 3D. Như vậy, vấn đề biến đổi mô hình sẽ được giới hạn trong nhiệm vụ biến đổi tọa độ của tập điểm trong mô hình đầu người 3D với những tham số nhất định.
Một đặc tả quan trọng được đưa ra cho vấn đề tạo hoạt cảnh đầu 3D là tập điểm trong chuẩn MPEG-4 [9]. MPEG-4 đặc tả các đặc điểm đầu người với 84 điểm đặc trưng (Hình 1a) đi kèm với các tham số hoạt hóa. Tập hợp các tham số này tương ứng với các cử chỉ của đầu người mà kết quả là gây ra sự biến dạng của mô hình đầu người so với trạng thái cân bằng trung tính. Từ việc xây dựng quá trình biến dạng của mô hình đầu người với các tham số hoạt hóa kết hợp với nhãn thời gian,ta có thể tạo ra hoạt cảnh của đầu người tương ứng. Vị trí các điểm đặc trưng được thiết lập tương ứng với các mốc trên đầu người như là miệng, mũi, mắt,… và chúng được sắp xếp theo từng nhóm.Một số nghiên cứu đã sử dụng tập điểm MPEG-4 trong các nghiên cứu của mình. Chẳng hạn, nhóm nghiên cứu của Turban [10] đã thực hiện áp dụng chuẩn MPEG-4 vào dữ liệu các bản quét 3D chất lượng cao từ video RGB-D Kinect. Nghiên cứu của nhóm hướng đến việc xây dựng các mô hình khuôn mặt chân thực và có thể áp dụng vào tạo chuyển động cho mô hình đầu người. Một nghiên cứu khác là của nhóm Itimad [11] với việc xây dựng một mô hình mặt 3D dựa theo chuẩn MPEG-4 và có chức năng đồng bộ hóa chuyển động môi phù hợp với dữ liệu âm thanh đầu vào. Nghiên cứu cũng áp dụng hàm Raised Cosine Deformation vào dữ liệu hình học khuôn mặt và triển khai ngôn ngữ EEMML (Emotional Eye Movements Markup Language) để hướng tới tính chân thực cho hoạt cảnh khuôn mặt. Năm 2015, nhóm nghiên cứu của Zhao [12] đã công bố một công trình về tổng hợp hoạt cảnh khuôn mặt 3D có cảm xúc dựa trên mô hình FCRBM (Factored Conditional Restricted Boltzmann Machines), từ chuỗi nhãn cảm xúc và tham số FAPs (Facial Action Parameters) ban đầu, kỹ thuật lấy mẫu Gibbs được áp dụng để lấy chuỗi FAPs tương ứng và sinh ra hoạt ảnh khuôn mặt 3D dựa theo đặc tả MPEG-4.
Gần đây, một nghiên cứu nhằm đồng bộ biểu cảm khuôn mặt với tiếng nói đã được đề xuất bởi nhóm Dahmani [13] vào năm 2019. Các tác giả đã áp dụng tiếp cận học sâu vào việc xây dựng một không gian nhúng. Từ dữ liệu văn bản đầu vào, các đặc tả xác định các tham số cảm xúc và áp dụng để điều chỉnh các tham số về nhãn thời gian, âm thanh cũng như hình ảnh.Tiếp đến vào năm 2020, nhóm nghiên cứu của Liu [14] đã nghiên cứu quá trình sinh biểu cảm gồm hai bước dựa trên tiếp cận tâm sinh lý. Cụ thể, các tác giả đã thực hiện xây dựng không gian dữ liệu dựa trên các chuyển động đơn vị của khuôn mặt và tạo ra các trạng thái biểu cảm khác nhau. Suzhen Wang [15] và đồng nghiệp đã đề xuất một bộ khung gồm các bước sau: Thực hiện tách chuyển động của đầu khỏi toàn khung hình chuyển động phụ thuộc âm thanh và dự báo chuyển động của đầu tương ứng với âm thanh, sau đó bộ tạo trường chuyển động sẽ sinh các điểm điều khiển chính từ âm thanh và tư thế đầu, cuối cùng tổng hợp lại thành video.
Hình 1. (a) Các điểm của chuẩn MPEG-4; (b)Sơ đồ chung của phương pháp đề xuất
Vào năm 2022, nhóm nghiên cứu của Chi [16] đã trình bày một kỹ thuật đồng bộ môi với lời nói trên cơ sở tạo hoạt cảnh khuôn mặt sử dụng “blendshape” và thử nghiệm trên nền tảng Unity sử dụng ngôn ngữ lập trình C#. Bài báo này đề cập đến việc biến đổi mô hình đầu người 3D tại các thành phần trên khuôn mặt nhằm mục tiêu tạo ra những sự thay đổi trên mô hình sao cho phù hợp với lời thoại đầu vào trên cơ sở đã được phân tích ra thành các âm tiết. Để làm được điều này, chúng tôi đã xây dựng một tập các mô hình mẫu đầu người 3D và sử dụng nó làm cơ sở để trích các vector biến đổi mô hình theo các biểu diễn âm tiết riêng lẻ. Với một lời thoại đầu vào được đại diện bởi tập chuỗi các âm tiết có nhãn thời gian, mô hình sẽ được biến đổi một cách tương ứng có trọng số để tạo ra được hoạt cảnh đầu ra tương ứng để thể hiện cử động của mô hình theo lời thoại. Phần còn lại của bài báo được cấu trúc nhưsau: phần 2 là các nội dung kỹ thuật đề xuất từ xây dựng mô hình đến các kỹ thuật biến đổi, phần 3 là thử nghiệm và cuối cùng là kết luận.
2. Kỹ thuật đề xuất
2.1.Sơ đồ chung
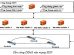
Chúng tôi đề xuất một bộ khung thực hiện gồm hai pha: pha chuẩn bị và pha xây dựng hoạt cảnh (Hình 1b).
Hình 2. Lược đồ tạo hoạt ảnh trong chương trình
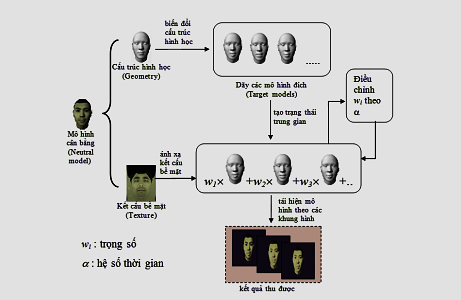
Pha chuẩn bị: Đầu tiên thực hiện xây dựng tập các mô hình mẫu đầu người 3D.Tập này gồm một mô hình cân bằng và các mô hình biểu diễn trạng thái đầu người 3D theo mỗi âm tiết tương ứng. Với mỗi cặp: mô hình cân bằng và một mô hình ứng với một âm tiết, ta sẽ trích rút được một tập các vector biến đổi một mô hình cân bằng sang một mô hình biểu diễn âm tiết tương ứng. Mỗi tập vector biến đổi này sẽ được lưu trữ lại thành file như một cơ sở dữ liệu để phục vụ cho việc biến đổi các mô hình khác sau này.
Pha xây dựng hoạt cảnh (hình 2):Trước tiên, mô hình cân bằng sẽ được nạp vào. Sau đó, mô hình này được biến đổi để tạo ra một tập các mô hình theo các âm tiết của lời thoại dựa vào các tập vector biến đổi để có được một dãy chỉ số mô hình xuất hiện trong hoạt ảnh. Cuối cùng, sử dụng kỹ thuật morphing để tạo ra sự chuyển biến trạng thái mềm mại giữa các mô hình để cho ra một hoạt cảnh.
2.2. Tập mô hình đầu 3D
Các mô hình đầu 3D được xây dựng làm dữ liệu cơ sở cho việc biến đổi tương ứng với lời thoại. Tập mô hình này bao gồm mô hình cân bằng và các mô hình biểu diễn trạng thái đầu người 3D theo mỗi âm tiết tương ứng. Mô hình cân bằng thểhiện trạng thái đầu người ở tình trạng trung tính, cụ thể định nghĩa như Bảng 1 dưới đây.
Bảng 1. Bảng các trạng thái đầu người ở tình trạng trung tính
| Tên bộ phận | Trạng thái |
| Cơ mặt | Tất cả cơ mặt đều thư giãn |
| Mắt | Các mí mắt tiếp tuyến với tròng đen Đồng tử (con ngươi) bằng 1/3 đường kính của tròng đen Các môi khép lại |
| Miệng | Đường giữa hai môi nằm ngang và có cùng độ cao với khoé môi. Miệng đóng và răng trên chạm vào răng dưới Lưỡi bằng, nằm ngang với đầu lưỡi chạm vào đường biên giữa răng trên và răng dưới |
Trong phạm vi nghiên cứu của bài báo, mô hình đầu người 3D được mô hình hóa dưới dạng là một tổng thể các bộ phận. Mỗi bộ phận là một đối tượng 3D, biểu diễn bởi một tập các điểm được phân bố theo trật tự nhất định, bao gồm một dạng hình học của đối tượng trong không gian 3 chiều, và một kết cấu bề mặt phủ lên bề mặt ngoài của dạng hình học đó. Cụ thể ở đây, dạng hình học của mỗi đối tượng là các lưới đa giác hình thành từ tập điểm trên. Khi xây dựng, mặt phẳng khuôn mặt song song với mặt phẳng Oxy và ánh mắt theo hướng trục Z. Các mô hình tương ứng với các âm tiết sẽ có cấu trúc dữ liệu giống với mô hình cân bằng nhưng có các trạng thái tọa độcác điểm trên bề mặt lưới khác biệt dựa theo mỗi biểu diễn khuôn mặt ứng với âm tiết.
2.3. Trích rút vector biến đổi theo âm tiết
Việc biến đổi mô hình từ trạng thái cân bằng sang trạng thái đích ứng với mỗi âm tiết thực tế là biến đổi các điểm trên mô hình theo mỗi vector tương ứng để tạo ra một biến thể của khuôn mặt. Để có được một mô hình đích mô phỏng một phát âm, những bộ phận sau trong mô hình sẽ được biến đổi: da mặt, hàm răng dưới, hàm răng trên, và lưỡi.Giả sử đã có N là tập điểm của mô hình cân bằng và T tập điểm của mô hình đích.
![]()
Ta cần tính ra tập vector V để biến đổi từ N sang T, cùng với tập chỉ số I tương ứng. Công thức tính như sau:
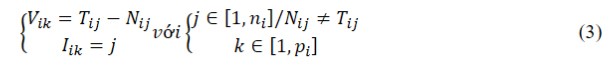
Trong đó:
– m: số bộ phận của mô hình chịu sự biến đổi.
– ni: số điểm trên bộ phận thứ i.
– pi: số vector biến đổi của bộ phận thứ i.
Dưới đây là thuật toán để tính vector biến đổi cho một phép biến đổi từ mô hình cân bằng sang một mô hình ứng với một âm tiết nào đó.
Thuật toán trích rút vector biến đổi:
– Input:
+ Neutral Model: Mô hình cân bằng.
+ Target Model: Mô hình được biến đổi theo âm tiết.
– Output:
+ vector: Tập vector biến đổi theo một âm tiết nào đó.
+ vec_index: Tập các chỉ số của điểm trên mô hình có vector biến đổi tương ứng trong tập vector.
(Còn tiếp ….)
Ghi chú: Kính mời Quý độc giả xem tiếp bài viết ở tệp PDF đính kèm bên dưới.
Nguồn: TNU Journal of Science and Technology, 228(15): 20-28
BAN BIÊN TẬP
https://sohoakhoahoc.com/
(04 /2024)
| Download file (PDF): Một kỹ thuật mô phỏng cử động của mô hình đầu người 3D theo lời thoại tiếng Việt (Tác giả: Trần Thanh Phương, Ngô Đức Vĩnh,Hà Mạnh Toàn, Đỗ Năng Toàn, Nông Minh Ngọc) |